


By Doina Vasilev, S2E Junior Data Scientist
Has anyone ever dreamed of talking with a legendary figure from our cultural past?
Our Advanced Analytics team at QuantiaS, business unit of S2E, turned this curiosity into a challenge: to reconstruct, via artificial intelligence, the dialogue with one of the giants of world literature, Dante Alighieri. By combining the charm of ancient 'bel parlare' with the power of modern technology, "DanteGPT" is an outstanding example of how, in the digital age, past can be breathed new life into.
DanteGPT: sonnet-replying artificial intelligence
Several articles are published every day on the subject of RAG (Retrieval Augmented Generation), a technology that enables ChatGPT to feed the business data it collects. RAG is very powerful and is the basis of one of our successful corporate products called Generative Shield [1].The purpose of today's presentation is to provide you with input on how to access the internal mechanisms of the LLM (Large Language Model) and customize them to your specific needs. Commercial models such as GPT-4 are black-boxes that can natively meet multiple business needs, yet there are use-cases that can only be solved by delving into the bowels of the neural network!
Did you ever try to make GPT-4 speak like Dante Alighieri, for example by asking it to translate a recipe for vegan carbonara into Florentine?
We have, and the results are far from optimal, as you can see in the box below.

While Open AI models have shown impressive capabilities in processing and generating modern English text, they face significant limitations when challenged to deal with languages and historical contexts that are not contemporary.
"DanteGPT" presents itself as a simple experiment specifically designed to train small models, other than Open AI, in the recognition and generation of languages characteristic of eras and styles not immediately accessible through commercial models.
So, how can you teach a small LLM to respond to a request as if it were Dante Alighieri?
Fine-Tuning with QLoRA
First of all, we choose a foundational model, such as Saiga-7b, a pre-trained open-source model specialised in the Italian language. The first step is fine-tuning on a dataset containing the entire Divine Comedy. Fine-tuning is the process of optimising the parameters of the model so that it performs a specific task; in our case, the aim is to obtain a chatbot that responds in the Florentine dialect of the 1300s. Due to this reason, the parameters of the pre-trained model will be updated and optimized using the dataset containing the entire Divine Comedy, which provides the model with a large number of examples of how to translate the language from Italian to Florentine dialect. IGenerally, the complete fine-tuning of parameters is an onerous process, so we will show you how to apply a quick customisation of the model, without having to re-train all its weights.
To achieve this, we use a PEFT (Parameter Efficient Fine Tuning) method called LoRA (Low-Rank Adaptation), which accelerates the parameter optimisation process: given a matrix W of dimension d and k, the decomposition done with LoRA will produce two matrices A(d x r) and B(r x k), where r is the hyper-parameter rank.
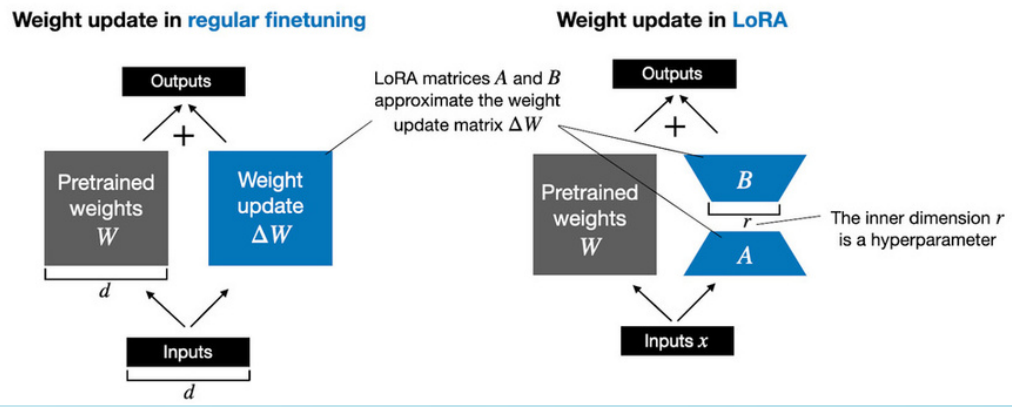
With this technique, the training process is sped up and made more accessible, with less than 1% of the total model parameters being changed.
Further reducing the required computational intensity, we use the quantised version of LoRA, QLoRA. During model loading, QLoRA applies an 8-bit floating point weight compression. Together, these two steps simplify the implementation and training of on-premises models, consuming only 15.7 GB of GPU RAM while reducing the required computational resources.
Application in DanteGPT
To facilitate learning, we structured the training dataset in the format:

In this way, we teach the model to translate from Italian into the Florentine vernacular, based on a dataset consisting of the text and paraphrase of the Divine Comedy.
We therefore launch the QLoRA with the parameters:
- Rank = 32
- Alpha = 64
The choice of the two parameters is one of the most critical and important aspects of the work. Firstly, the rank selection determines how much information is transferred from the original matrix W to the two submatrices A and B. Setting a high rank value has the benefit of increasing the accuracy of the results, but may lead to overfitting and too high a consumption of computational resources. Based on our experiments, a rank of
32 leads to optimal results.
On the other hand, alpha is a coefficient for normalising the weights. From our experience, we obtain optimal results by setting the alpha as 2*rank.
Finally, after running the model for an hour, we can compare the results with ChatGPT.
Repeating the initial question posed to ChatGPT "Can you give me the recipe for vegan carbonara" DanteGPT replied as follows.

As can be seen from the response, it traces the sonnet style of Dante Alighieri while retaining the assistant capabilities of Saiga-7b. You can find the resources used, models and datasets in the following link.
If you have any questions or concerns, please do not hesitate to contact the author of this article: Doina Vasilev
Together with the QuantiaS Advanced Analytics team, she will be pleased to answer your questions and assist in reproducing this experiment.
Solutions and Applications
Despite starting this experiment with the intention of exploring the potential of AI technologies for cultural and research purposes, we are not blind to the interesting commercial opportunities that may be opened up as a result.
Indeed, the innovative methodologies employed to create DanteGPT not only allow us to emulate specific linguistic styles of past eras or famous authors, but also provide the tools to create chatbots with unique personalities, capable of making interactions with brands immersive experiences, building distinctive communicative identities and helping to structure a dialogue that goes beyond the simple transaction. At the same time, the same techniques allow us to create highly specialised chatbots, capable of navigating and using the specific vocabulary of numerous professional sectors, such as legal, medical, administrative, and other similar fields where accuracy of terminology is imperative.
This extreme personalisation can open up new horizons in marketing, customer service, content creation and much more. Experiments like DanteGPT offer business opportunities that can transform the way companies interact with their audiences, promoting deeper engagement and stimulating a unique brand experience.
Moreover, we invite you to visit our website to discover all of our AI solutions, including Generative Shield [1], a cloud-based SaaS platform that utilizes all serverless services and resides in the Amazon Web Services cloud. Through the use of RAG, it is highly scalable and enables highly competent conversational agents to be created.




Blog comments